How Matt Cutts spreads PR evenly on 977 posts and counting
In a previous post we did, on how PageRank decays on sites, we detailed how posts found 3-5 levels deep really lose their PageRank down to almost nothing. We’ve recently uncovered a weird setup Matt Cutts employs on his blog. We actually came across this after having an internal discussion on how to evenly distribute PageRank on a blog with a large number of posts. Matt has posted 977 times since July 2005 so this seemed like THE go to resource for best practices. What we uncovered is both mysterious and intriguing.
NOINDEX your duplicate content pages:
By now, most SEO’s are consciously paranoid about duplicate content. Panda sufficiently scared webmasters enough to start worrying about where content appears and reappears on their sites. As a result of this, it’s largely considered best practice to limit the number of indexable taxonomies (tags, categories, date archives) in blogs.
Date Archives
Matt doesn’t disappoint by following this practice; his date archives are linked in his sidebar but the date pages employ meta robots NOINDEX, NOFOLLOW – meaning these pages will not be indexed or appear in search results. This obviously makes sense from a searcher perspective, is there ever really a relevant query that should be sent to the ‘October 2005’ date archive page on Matt’s blog?

Not really – a searcher wanting to see Matt as Inigo Montoya might search for “Matt Cutts Inigo Montoya” and therefore the query should result with the post page, not the date archive.
Tag taxonomies:
Matt has decided not to use tags at all for his blog. Tags can become useful when your site has thousands of posts and an argument could be made for his site being easier to navigate with them, but in reality tags just aren’t that helpful when you can just Google search. No links or tag pages exist on Matt’s Blog, but if you decide you want to use tags, you’ll need to decide if the tags or the categories are better for Google’s index. In all likelihood it should be your categories unless your very stingy with your tagging.
Category Taxonomies:
Matt decided to allow indexation of his category pages. I think this makes a lot of sense for his blog. I also assumed that he would use diverse enough categorization that the pagination of his categories would be minimal. I was wrong! Matt’s Google/SEO category is a whopping 542 posts deep. He permits category pages to display the 5 most recent articles, which means in order to reach his oldest SEO category post, you would need to click on the ‘Previous Entries’ link at the bottom of his category page a total of 108 times.
From a PageRank flow perspective, I was shocked. In what world would Google-bot actually click all the way through his site to reach those posts that are buried that deep in a category pagination?
Another interesting issue is that Matt uses a Meta Robots NOINDEX,NOFOLLOW on all pagination, so his Page 2 through Page 109 category archive pages are not crawlable or indexable by Google. This further alienates all those posts in a given category.
PageRank flow and depth on Matt’s blog:
Once I discovered that some of the categories on Matt’s blog were so massively buried, I knew I was missing something. Matt Cutts obviously has lots of inbound links from powerful sites all over the web. Open Site Explorer shows over 18,000 linking root domains with more than 440,000 total links into Matt’s blog.
A good portion of Matt’s 977 posts probably have inbound links to them that would allow Google-bot in and bring it back occasionally That said, I would be very surprised if Matt so blatantly cannibalized his PageRank flow. Not only should his site structure make it very difficult for Google-bot to find his deepest posts, it should make his inbound links distribute their authority very poorly throughout the site. Surely this just wouldn’t be how Matt intended the site to operate and index.
Google-bot and the random surfer:
We continued our research, knowing that up to this point, we simply must have missed something important. That’s when we found links on each of Matt’s posts, beneath the comments, to the ‘Previous and Next’ post. These 2 links are followed, and this would allow Google-bot and Pagerank to flow through the site a bit more.
Google-bot is said to crawl the web like a random surfer might. It reaches a page, finds links and then crawls those links. Occasionally, it decides it’s no longer interested and it wanders off to a new section of the web. That is a overly simplistic model of how Google crawls the web but it demonstrates the importance of depth for crawler behavior. Eventually, after your pages reach a certain level of depth, Google’s going to get bored and run off to play with someone else’s site. So when we found Matt’s ‘Previous and Next’ we decided to take a closer look:
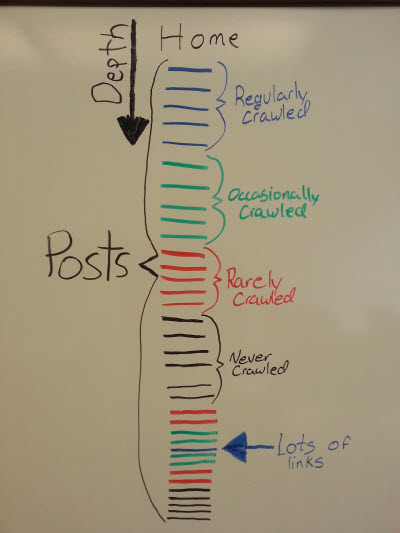
The above image illustrates how a lot of posts could be somewhat disconnected from a site when Matt Cutts’ Meta Robots NOINDEX,NOFOLLOW’s the paginated categories on his site. The crawlers will very rarely ever reach those posts that don’t have inbound links from external sites.
We analysed Matt’s site and as we suspected, there are a lot of posts 5 levels or deeper, but we were surprised to see how few posts landed 10 levels deep or lower.
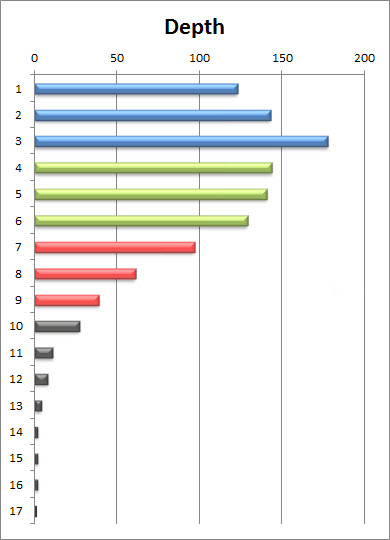
Having now established that the vast majority of posts are not necessarily outside of crawlers range, and considering the external site linking that is not shown in our graph above, Google-bot should be crawling the site with relative ease.
Keep in mind, since Google’s Caffeine update, Google has become equipped with the infrastructure to really dive deep in their crawls. If this had been Matt’s implementation prior to caffeine, there might have been more concern for those pages 7 levels deep or deeper.
PAGERANK DECAY:
With the crawler concerns diminished, we then moved on to investigating if Matt was cannibalizing PageRank from so many posts. Keep in mind, most of Matt Cutt’s posts were 4 levels deep or deeper. Posts that are 4 levels deep or deeper, decays PageRank by more than 99.9%.
We continued our research, knowing that up to this point, we have simply had to have missed something important. That’s when we started to review the code more closely. Matt is using Rel=Next & Rel=Prev connecting each and every post. This makes things very interesting.
Here’s was Google has to say about Rel=Next & Rel=Prev:
Consolidate indexing properties, such as links, from the component pages/URLs to the series as a whole (i.e., links should not remain dispersed between page-1.html, page-2.html, etc., but be grouped with the sequence).
This statement is obviously in reference to the more common implementation of Rel=Next & Rel=Prev where there is a numerical list of products or search results for example. Picture a product list with 10 products per page and a total of 50 products in a Paginated list of 5 pages. Google recommends you use Rel=Next & Rel=Prev to connect those pages resulting in the 50 products each receiving the same PR, even those products on page 5.
In the case of Matt Cutts – the 977 posts on his blog are all connected via Rel=Next & Rel=Prev. If you extend the logic from Google’s statement, they are essentially saying that Google will combine all 977 posts in his series into a single entity with all of the PageRank being combined and spread evenly across the series of posts. That sounds alarming since it would essentially pool all of the PageRank to each post individually then divide that PageRank out to every post. This would make Make Cutts blog only 2 levels deep from a PageRank calculation standpoint.
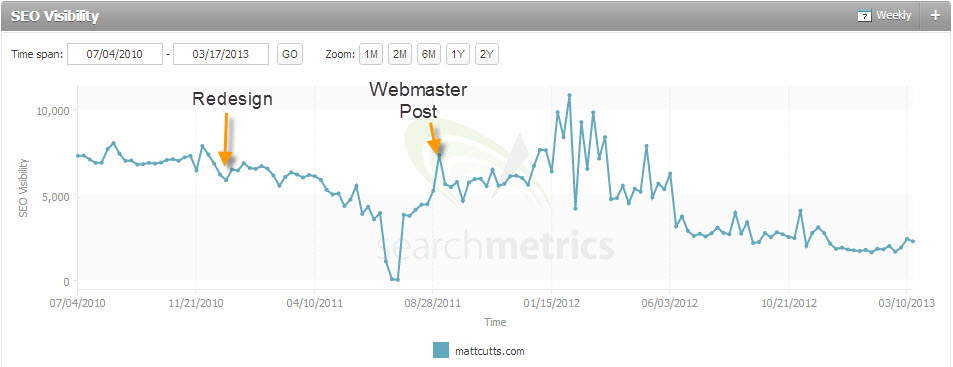
We decided to look at when Matt implemented Rel=Next & Rel=Prev on his posts to see if that correlated to the Google Webmaster Central post highlighting this new use for the old HTML markup. Matt implemented a new design to his blog between Nov 2009 and Jan 2010 and the Webmaster Central post was published in Sept. 2011. Obviously Matt added the Rel=Next & Rel=Prev well before the announcement.
Next we looked at Matt’s Blog’s performance in search. Matt saw an uptick in traffic around the time that Webmaster Central created their post but it seemed to normalize shortly after. This could be an indicator that Matt’s site began to perform well, so when Matt investigated. It could also be an anomaly or problem with the data so it’s hard to say this had any significant impact on his site’s performance.
Ultimately, this method of structuring a site, especially a blog, seems very effective. If you can string your posts into a series using Rel=Next & Rel=Prev then this can be a great opportunity to optimize your PageRank flow.
In fact, most WordPress themes include Rel=Next & Rel=Prev functionality pre-built. You’ll just need to ensure you’re keeping your index size down by selecting 1 form of taxonomy and noindex,nofollow the others. I recommend SEO Ultimate – this plugin makes managing your indexable taxonomies very easy for WordPress.
