
What to Do When Your Testing Data Isn’t Just Useless, But It’s Actually Making Things Worse
 Me, right before realizing that my data is invalid
Me, right before realizing that my data is invalid
(Photo courtesy United Artists/Red Bank Films).
Ever get that feeling when you realize that the data you’re working with is bunk?
It’s a sinking feeling in your stomach, somewhere between the “I should have gone to law school” feeling and realizing that your high school prom date took you to the dance as a joke.
As online marketers, we’re married to our data, and that’s especially true when it comes to the testing we do. Good numbers are the basis for good decisions, but when bad data makes it into the mix, that marriage can lead down a road of bad decisions that can only end in disaster.
How can you keep from making those bad decisions and getting that bad data feeling? It’s all about being methodical in your testing.
When a winner is really a loser
For testing everything from ad copy to new landing pages, most marketers favor a simple setup. You run some traffic to each of your test versions, count the successes and compare the results. This is referred to as a frequentist setup.
So, let’s say I’m running a split test on ad copy and I get results like this:
Control – 15 impressions, 4 clicks
Variation – 14 impressions, 5 clicks
A 34% improvement! Voila! Time to ask for a raise.
Problem is, this data isn’t much to go on. It’s possible that the variation is actually worse and it just got a few impressions from motivated visitors who would have clicked no matter what the ad looks like.
When comparing your results, you have to also consider statistical significance. Did your variation actually produce an improvement, or was it just your sampling?
Why statistical significance is… significant
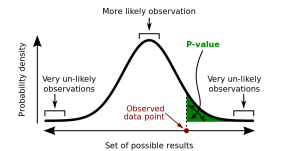
In any testing you do, there is a chance that natural differences in sampling will create a difference in the observed effect. Those motivated visitors I mentioned above are an example.
The way to control for this is by factoring significance of your data into your decision. For the purposes of online marketing, you do this by first finding the likelihood that an A/A test — testing the control against the control — would produce a result as extreme or more extreme than the one you got. This is called the p-value.
(If you’re interested in finding out how to calculate your p-values manually, here is a handy guide from Penn State. However, for the purposes of this blog, we’ll keep things fairly simple.)
In the example above, we have a p-value of 0.3, or a 30% chance we would have seen the same result on an A/A test. Now that we have our p-value, we compare it against a pre-set threshold to determine significance.
The standard is typically 5%, but depending on the test, some marketers go as low as 1%. So, looking at the example above, we don’t know if the ad copy change actually produced the improvement.
Let’s crank up the traffic
Let’s try another example. I did some split testing on a high traffic landing page over the course of an afternoon. Here’s what I found:
Control – 14,631 visitors; 345 conversions
Variation – 14,154 visitors; 408 conversions
We have a 22% improvement with a p-value less than 1%. (You’ll often see marketers express this as 1 minus the p-value, so our test is reported at “100% significance.” Also, here’s a good opportunity to link this awesome A/B significance calculator from KissMetrics).
We’re up 22%! Time for my raise, right? Not quite.
If I only performed this test over the course of an afternoon and shut it off as soon as I saw it hit significance, I allowed myself to bias the results of the test. Traffic patterns vary by hour, day and even by season. The type of shopper who lands on an ecommerce site during the work day might behave differently than one browsing at home on a weekend evening.
If I’m running multiple variations on this landing page, I might see different variations dip and dive throughout the course of the week.
Setting your durations up for success

The way to prevent yourself from biasing the results of your testing is to work around pre-set time durations or sample sizes.
If you know that virtually every kind of visitor will pass through your test over two weeks, you can set that as a simple duration. A month might be more appropriate for some situations. Find out what cycles your business runs in and base your durations around that.
Another option is to use a predetermined sample size. If you know what kind of improvement you’re looking for, you can run a test until you have hit your sampling limit and make a determination after that.
Here is a handy A/B sample size calculator from the folks at Optimizely.
Wrapping things up
Testing is a great way to drive better performance out of what you’re already doing, but it only works if it’s done right. Keep your methodology sound, and you’ll have fewer of those nasty “bad data” feelings.
{kind=link}